
LLMs are powerful but have some obvious drawbacks, such as hallucination problems, poor interpretability, inability to grasp key issues, and privacy and security concerns. Retrieval-Augmented Generation (RAG) can significantly improve the quality and practicality of LLM-generated results.
Further Reading: What is RAG?
RAG technology breakthrough limits of LLM, combining “information retrieval” and “text generation” to dynamically acquire knowledge and significantly improve
This month, Microsoft launched the strongest RAG knowledge base open-source solution, GraphRAG, which became a hit upon release.
- Project link: https://github.com/microsoft/graphrag
- Official website: https://microsoft.github.io/graphrag/
Some say it is more powerful than ordinary RAG:
GraphRAG uses LLM to generate knowledge graphs, significantly improving QA performance, especially when dealing with private data.
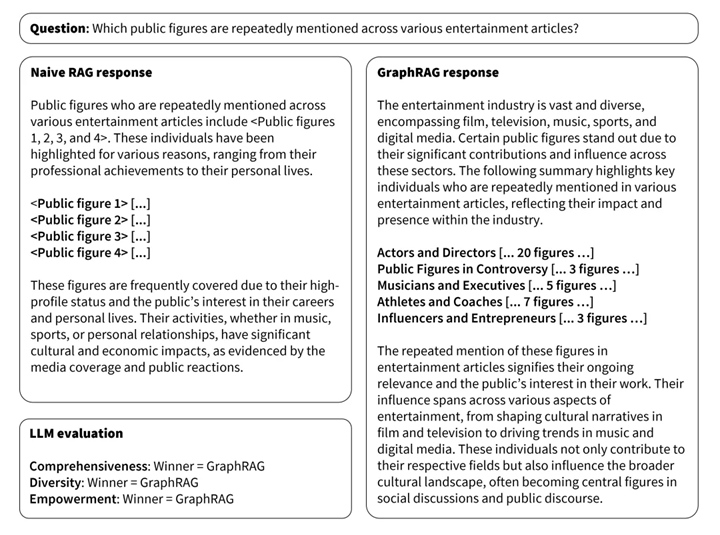
▲ GraphRAG vs Traditional RAG
Currently, RAG is a technique that improves LLM output using real-world information and is a crucial part of most LLM-based tools. Generally, RAG uses vector similarity as a search method, known as Baseline RAG. However, Baseline RAG doesn’t perform well in certain situations, such as:
- Connecting different points when answering questions that require traversing shared attributes across different information fragments to provide new synthesized insights.
- Fully understanding summary semantic concepts in large data sets or even single large documents.
Microsoft’s GraphRAG creates a knowledge graph based on the input text corpus, enhancing the prompt during queries with community summaries and graph machine learning outputs. GraphRAG shows significant improvements in answering the above types of questions and performs better when handling private data sets.
However, as people delve deeper into GraphRAG, they find its principles and content hard to understand.
The GraphRAG Manifesto by Neo4j CTO Philip Rathle
Recently, Philip Rathle, CTO of Neo4j, published an article titled “The GraphRAG Manifesto: Adding Knowledge to GenAI,” which explains GraphRAG’s principles, differences from traditional RAG, and advantages in simple language.
Philip Rathle, Neo4j CTO

▲ Neo4j CTO Philip Rathle
He states: “Your next generative AI application will likely use a knowledge graph.”
We are gradually realizing that to unlock the true value of generative AI, we cannot solely rely on autoregressive LLMs for decision-making. Technologies like vector-based RAG and fine-tuning can help but may fail miserably in certain application scenarios.
For many questions, the solutions of vector-based RAG (and fine-tuning) essentially increase the probability of correct answers but lack the certainty of correctness. They often lack background information and fail to connect with what you already know. Additionally, these tools do not provide clues for understanding specific decisions.
Google’s Second-Generation Search Engine
Back in 2012, Google introduced its second-generation search engine and published a symbolic blog post “Introducing the Knowledge Graph: things, not strings.” They found that by using a knowledge graph to organize the things represented by strings in all web pages, they could significantly improve search.
Today, the generative AI field is encountering a similar pattern. Many generative AI projects hit bottlenecks because their generated results are limited to processing strings rather than things. Breaking this bottleneck requires incorporating knowledge graphs.
Understanding Apple from Human, Vector, and Graph Perspectives

▲ Human, Vector, and Graph Perspectives of Apple
In human terms, Apple’s representation is complex and multidimensional. Vector representation of this apple is an array that captures the essence of its corresponding text in an encoded form.
Knowledge Graphs in GraphRAG
Knowledge graphs represent the world declaratively, in symbolic AI terms, allowing both humans and machines to understand and reason about them. They can be queried, visualized, annotated, modified, and extended, serving as world models for your work domain.
GraphRAG uses both vector and graph queries, enhancing the RAG process. The core model is simple: it includes a knowledge graph layer along with the typical vector search.
GraphRAG Model
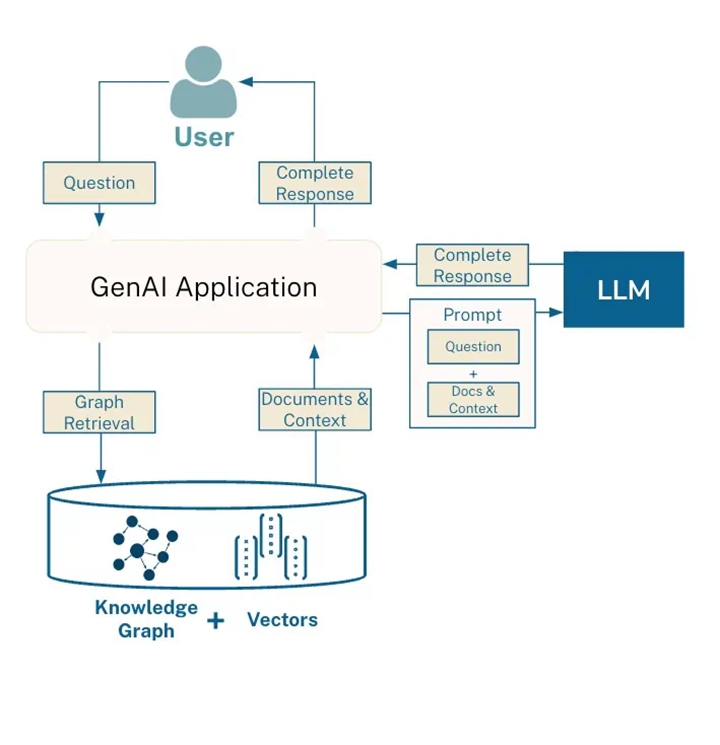
▲ Common GraphRAG Model
The Lifecycle of GraphRAG
Generative AI applications using GraphRAG follow a lifecycle similar to any RAG application, starting with a “create graph” step:
GraphRAG Lifecycle
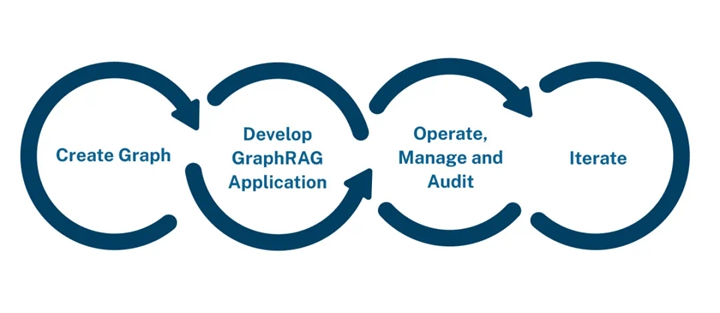
▲ GraphRAG Lifecycle
Creating the graph is similar to chunking documents and loading them into a vector database. The development and advancement of tools have made graph creation relatively simple. Here are three good news:
- Graphs are highly iterative—you can start with a “minimum viable graph” and extend it.
- Once the data is added to the knowledge graph, it can be easily evolved. You can add more types of data to achieve and leverage network effects and improve data quality to enhance application value.
- The field is rapidly advancing, meaning that as tools become more sophisticated, graph creation will become increasingly easy and straightforward.
Adding the graph creation step to the previous image gives the following workflow:
GraphRAG Workflow with Graph Creation Step
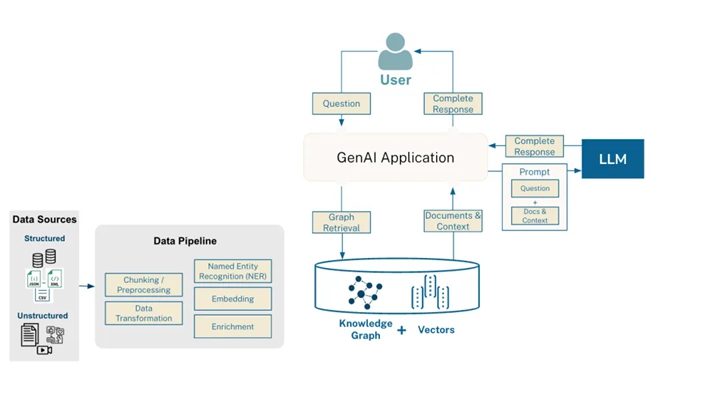
▲ GraphRAG Workflow with Graph Creation Step
Why Use GraphRAG?
GraphRAG offers three main advantages over vector-only RAG:
- Higher accuracy and more useful answers (execution time/production advantage).
- Easier to build and maintain RAG applications once the knowledge graph is created (development time advantage).
- Better explainability, traceability, and access control (governance advantage).
1. Higher Accuracy and More Useful Answers
GraphRAG’s first and most visible advantage is its higher response quality. Both academia and industry provide many examples supporting this view.
For example, a study by Data.world in late 2023 showed that GraphRAG could triple LLM response accuracy across 43 business questions. This benchmark study provides evidence that knowledge graphs can significantly improve response accuracy.
Improvement in Response Accuracy by Knowledge Graphs

▲ Improvement in Response Accuracy by Knowledge Graphs
Microsoft also provides evidence, including a February 2024 research blog “GraphRAG: Unlocking LLM discovery on narrative private data” and the related research paper “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” and software: https://github.com/microsoft/graphrag.
They observed two issues with baseline vector RAG:
- Difficulty connecting points. To synthesize different information for new insights, it is necessary to traverse different information fragments through shared attributes, at which point baseline RAG fails to connect the different fragments.
- Poor performance in understanding summarized semantic concepts in large data sets or even single large documents.
Microsoft found that “using knowledge graphs generated by LLM, GraphRAG can significantly enhance the ‘retrieval’ part of RAG, filling the context window with more relevant content, leading to better answers and source evidence.” They also found that compared to other alternatives, GraphRAG required 26% to 97% fewer tokens, resulting in not only better answers but also lower costs and better scalability.
Going deeper into accuracy, we know that the correctness of answers is important, but usefulness is also crucial. People find that GraphRAG not only improves the accuracy of answers but also makes them richer, more complete, and more useful.
A recent paper by LinkedIn “Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering” is an excellent example, describing the impact of GraphRAG on their customer service application. GraphRAG improved the correctness and richness of customer service answers, making them more useful and reducing the median time to resolve each issue by 28.6%.
Neo4j’s generative AI seminar also provided a similar example. Here is a comparison of answers to a set of SEC filings using the “vector + GraphRAG” and “vector only” methods:
Comparison of “Vector Only” and “Vector + GraphRAG” Methods
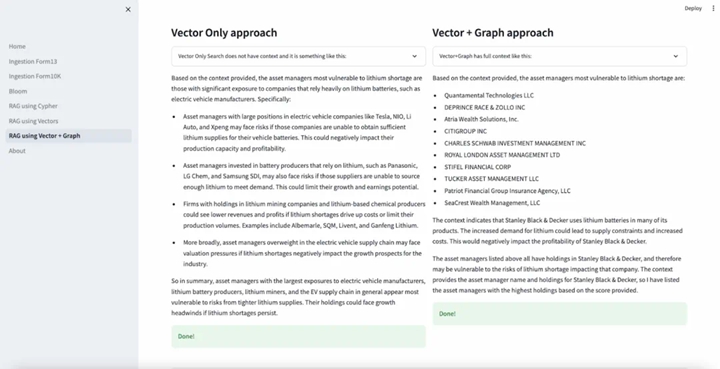
▲ Comparison of “Vector Only” and “Vector + GraphRAG” Methods
Note the difference between “describing the characteristics of companies that may be affected by lithium shortages” and “listing specific companies that may be affected.” If you are an investor wanting to rebalance your portfolio based on market changes or a company wanting to adjust your supply chain based on natural disasters, the information on the right is much more important than the left. Here, both answers are accurate, but the one on the right is clearly more useful.
2. Enhanced Understanding and Faster Iteration
Knowledge graphs are intuitive both conceptually and visually. Exploring knowledge graphs often brings new insights.
Many knowledge graph users share the unexpected benefit that once they have invested in creating their knowledge graph, it unexpectedly helps them build and debug their generative AI applications. Part of the reason is that viewing data in the form of graphs reveals a vivid data landscape underlying these applications.
Graphs allow you to trace answers, find data, and follow the causal chain.
Consider the above example of lithium shortages. If you visualize the vectors, you get something like the image below, but with more rows and columns.
Vector Visualization
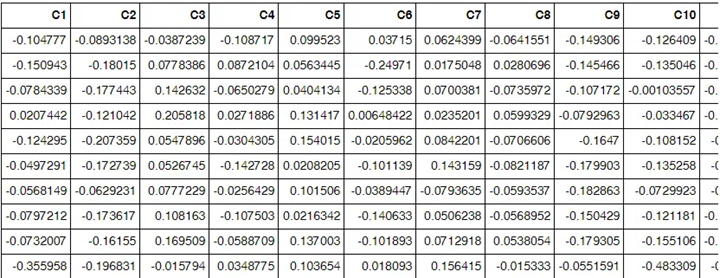
▲ Vector Visualization
However, if you convert the data into graphs, you can understand it in a way that vector representation can’t.
Below is an example from a recent webinar by LlamaIndex, demonstrating their ability to extract vectorized word blocks (lexical graphs) and entities extracted by LLMs (domain graphs) and link them together using “MENTIONS” relationships:
Extracting Lexical and Domain Graphs
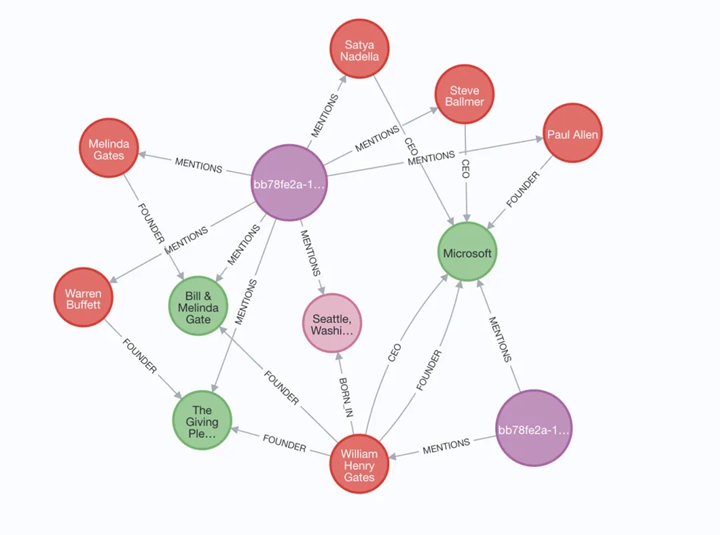
▲ Extracting Lexical and Domain Graphs
(There are many other examples using tools like Langchain, Haystack, and SpringAI.)
You can see the rich structure of the data in this image and imagine the new development and debugging possibilities it brings. Each piece of data has its own value, and the structure itself stores and conveys additional meaning, which you can use to enhance the intelligence level of the application.
This is not just visualization. It also allows your data structure to convey and store meaning. Below is the reaction of a developer from a well-known fintech company when they introduced knowledge graphs into their RAG workflow for just one week:
Developer’s Reaction to GraphRAG

▲ Developer’s Reaction to GraphRAG
This developer’s reaction aligns with the “test-driven development” hypothesis: verify (not trust) whether the answer is correct. Personally, I would feel uneasy giving complete control to an AI with entirely opaque decisions. Specifically, even if you are not an AI doomsday theorist, you would agree that it is valuable to ensure that “Apple, Inc.” word blocks or documents are not mapped to “Apple Corps” (these are two completely different companies). Since data ultimately drives generative AI decisions, ensuring data accuracy is crucial.
3. Governance: Explainability, Security, and More
The greater the impact of generative AI decisions, the more you need to persuade those ultimately responsible when decisions go wrong. This often involves auditing each decision. This requires a reliable and repeatable record of good decisions, but that’s not enough. When adopting or rejecting a decision, you also need to explain its reasoning.
LLMs themselves can’t do this well. Yes, you can refer to the documents used to get the decision, but these documents don’t explain the decision itself—let alone that LLMs may fabricate references. Knowledge graphs are on another level entirely, making the reasoning logic of generative AI clearer and easier to explain.
Continuing the example above: Lettria’s Charles extracted entities from 10,000 financial articles and loaded them into a knowledge graph, paired with an LLM to execute GraphRAG. We see this indeed provides better answers. Let’s look at this data:
Loading Entities Extracted from 10,000 Financial Articles into a Knowledge Graph
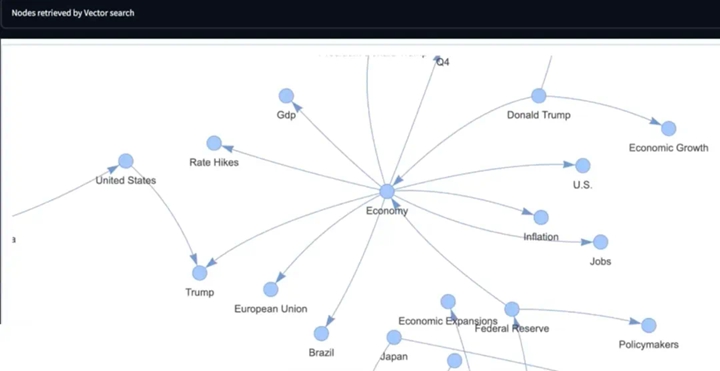
▲ Loading Entities Extracted from 10,000 Financial Articles into a Knowledge Graph
First, view the data as graphs. Additionally, we can navigate and query this data, and correct and update it at any time. Its governance advantage is that it becomes much simpler to view and audit this data’s “world model.” Compared to the vector version of the same data, using graphs makes it more likely for the ultimate decision-makers to understand the reasoning behind the decisions.
In terms of ensuring quality, placing data in a knowledge graph makes it easier to find errors and unexpected issues and trace their sources. You can also obtain source and confidence information in the graph and use it for calculations and explanations. The vector version of the same data simply can’t achieve this, as we’ve discussed before, even most people (including not-so-common people) find it hard to understand vectorized data.
Knowledge graphs also significantly enhance security and privacy.
When building prototypes, security and privacy are usually not very important, but when turning them into products, they are crucial. In regulated industries like banking or healthcare, employees’ data access permissions depend on their roles.
Both LLMs and vector databases lack good ways to restrict data access. Knowledge graphs provide an excellent solution, regulating the scope of participants’ access to the database through permission controls, preventing them from seeing data they are not allowed to see. Below is a simple security principle that can be implemented in a knowledge graph:
A Simple Security Principle that Can Be Implemented in a Knowledge Graph
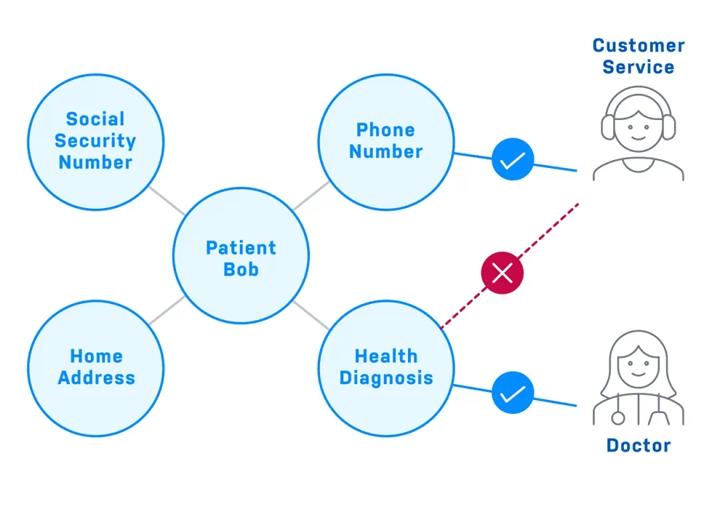
▲ A Simple Security Principle that Can Be Implemented in a Knowledge Graph
Creating Knowledge Graphs
What does it take to build a knowledge graph? The first step is to understand the two types of graphs most relevant to generative AI applications.
Domain Graph represents the world model related to the current application. Here is a simple example:
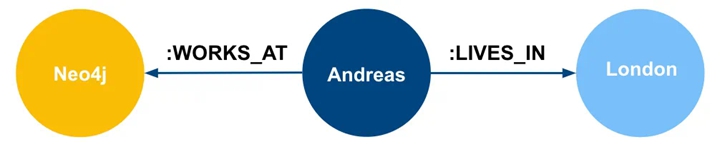
▲ Domain Graph
Lexical Graph represents the structure of documents. The simplest lexical graph consists of nodes formed by text blocks:
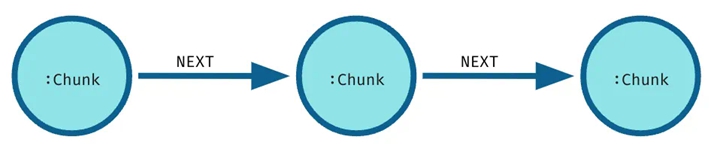
▲ Lexical Graph
People often expand it to include relationships between text blocks, document objects (such as tables), chapters, paragraphs, page numbers, document names or numbers, document collections, sources, etc. You can also combine domain and lexical graphs, as shown below:
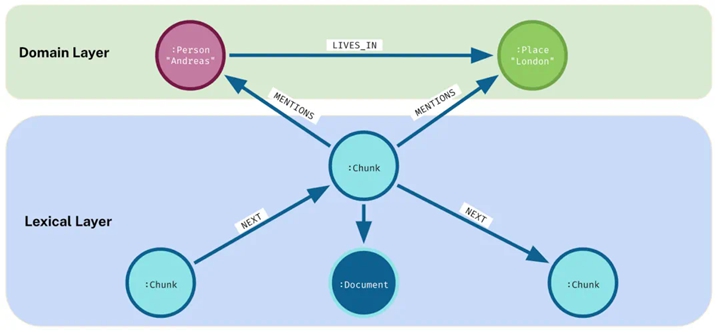
▲ Combining Domain and Lexical Layers
Creating a lexical graph is simple, mainly involving parsing and chunking. For domain graphs, the creation path varies based on the data source (structured, unstructured, or both). Fortunately, tools for creating knowledge graphs from unstructured data sources are rapidly evolving.
For example, the new Neo4j Knowledge Graph Builder can automatically create knowledge graphs using PDF files, web pages, YouTube videos, and Wikipedia articles. The process is very simple—just a few clicks, and you can visualize and query the domain and lexical graphs of the input text. This tool is powerful and fun, significantly lowering the threshold for creating knowledge graphs.
For structured data (such as customer, product, and location data stored by your company), it can be directly mapped into a knowledge graph. For example, for the most common structured data stored in relational databases, standard tools can be used to map relationships into graphs based on proven reliable rules.
Using Knowledge Graphs
With a knowledge graph, you can perform GraphRAG, and there are many frameworks available for this, such as LlamaIndex Property Graph Index, Langchain integrated with Neo4j, and the version integrated with Haystack. The field is advancing rapidly, but the programming methods are becoming very simple.
The same is true for graph creation. Tools like Neo4j Importer (a graphical interface for importing and mapping tabular data into graphs) and the aforementioned Neo4j Knowledge Graph Builder are emerging. The image below summarizes the steps for building a knowledge graph.
Automatically Building Knowledge Graphs for Generative AI
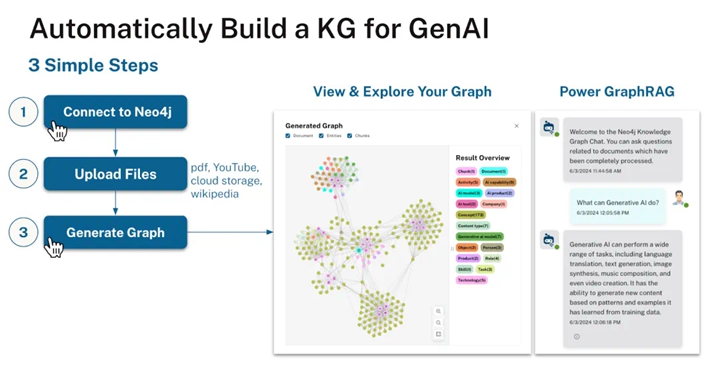
▲ Automatically Building Knowledge Graphs for Generative AI
Using knowledge graphs also allows mapping human language questions into graph database queries. Neo4j released an open-source tool, NeoConverse, to help query knowledge graphs using natural language.
While learning to use graphs initially requires some effort, the good news is that as tools evolve, it will become easier.
Conclusion: GraphRAG is the Future of RAG
LLMs’ inherent word-based computation and linguistic skills combined with vector-based RAG can yield excellent results. To achieve stable good results, we must go beyond strings and build world models on top of word models. Similarly, Google found that to master search capabilities, they had to go beyond text analysis and map the relationships between the things represented by strings. We see the same pattern emerging in the AI world. This pattern is GraphRAG.
Technological development follows an S-curve: when one technology reaches its limit, another takes over. As generative AI continues to evolve, application demands are also increasing—from high-quality answers, explainability, to fine control of data access, privacy, and security, the value of knowledge graphs is becoming increasingly evident.
The Evolution of Generative AI
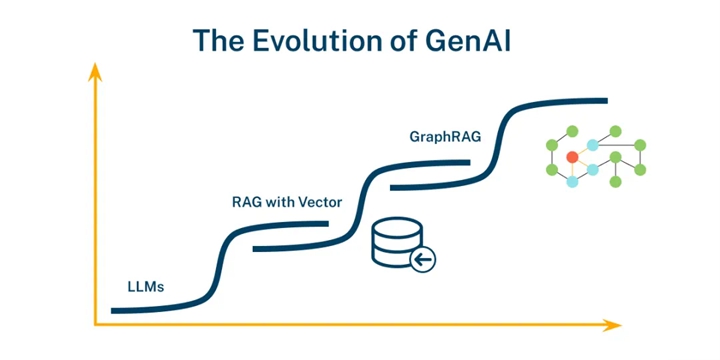
▲ The Evolution of Generative AI
Your next generative AI application will likely use a knowledge graph.

Leave a Reply